
Software Programming

UI/UX Design
Development Agency
Web Development
Innovative Ideas
Programming
App Development
Software Programming
UI/UX Design
Development Agency
Web Development
Innovative Ideas
Programming
App Development
Software Programming
UI/UX Design
Development Agency
Web Development
Innovative Ideas
Programming
App Development
About The Project
AWS DataFlow Migration Specialist
Seamless Data Migration from Legacy to Cloud with Continuous Synchronization
Quick Facts
| Feature | Capability |
|---|---|
| Migration Timeline | 2-4 weeks for multi-terabyte databases |
| Production Downtime | 15-30 minutes (final cutover only) |
| Data Consistency | 99.99% with automated validation |
| Supported Sources | PostgreSQL, MySQL, Oracle, SQL Server, MongoDB |
| Storage Cost Savings | 60-70% annual reduction vs on-premises |
| Replication Latency | Sub-second CDC updates (continuous sync) |
| IaC Options | CloudFormation (YAML) or Terraform (HCL) |
Core Migration Capabilities
This platform delivers enterprise-grade data migration through four distinct operational modes, each optimized for different database scenarios and business requirements.
Full Load Migration
Initial snapshot of entire source database transferred to S3 data lake in parallel streams. Optimized for large table sets with configurable parallelism (4-8 concurrent threads). Ideal for one-time migrations or as foundation for continuous replication. Multi-threaded architecture handles terabyte-scale transfers efficiently.
Change Data Capture (CDC)
Continuous replication of database changes from source to S3 with sub-second latency. Automatically captures INSERT, UPDATE, and DELETE operations. Enables zero-downtime cutover by maintaining parallel systems during transition. Perfect for high-volume transaction databases requiring constant synchronization.
Heterogeneous Database Conversion
Convert between different database engines: MySQL to Aurora PostgreSQL, Oracle to RDS, SQL Server to Aurora MySQL. Native schema transformation with automatic data type mapping. Minimizes application code changes required for cloud adoption.
Data Lake Consolidation
Migrate multiple disparate databases into unified S3 data lake with Parquet columnar format. Enable cross-database analytics and reporting. Automatic partitioning by time and dimension for optimized query performance. Foundation for modern BI and analytics workloads.
Architecture Visualization
AWS DataFlow Stack Components
The dataflow-stack.yaml CloudFormation template deploys the complete infrastructure:
- S3 Data Lake: Primary versioned, encrypted storage for migrated data with lifecycle policies
- S3 Staging Bucket: Temporary transformation area with auto-cleanup after 90 days
- CloudWatch Logs: Real-time monitoring of migration progress and data quality metrics
- IAM Roles & Policies: Secure access control with principle of least privilege
- Security & Encryption: KMS keys, VPC isolation, complete audit trails
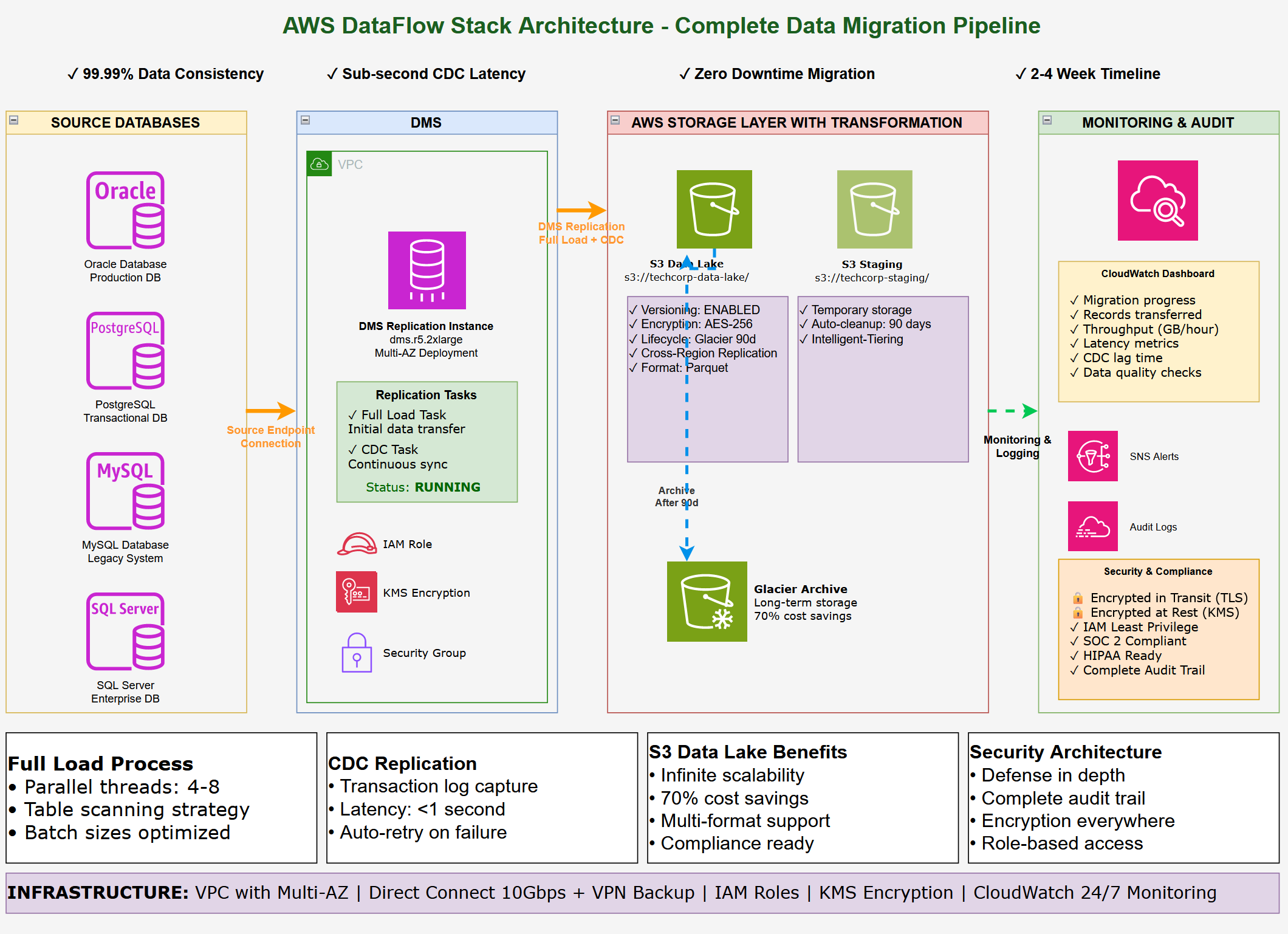
Figure 1: Complete data migration stack from source database through DMS to S3 data lake with monitoring and security controls
Data Flow Architecture
End-to-end data pipeline from source database to cloud storage with built-in monitoring, validation, and governance.
Source → DMS → Target Pipeline
- Source Database: On-premises or cloud database (any supported engine)
- Connection: Direct Connect (10Gbps) or VPN for secure connectivity
- DMS Replication: AWS-managed data migration engine with automatic failover and monitoring
- S3 Data Lake: Versioned, encrypted, and lifecycle-managed storage for analytics
- Staging Bucket: Temporary transformation area with automatic cleanup policies
- Monitoring: Real-time CloudWatch metrics and comprehensive CloudTrail audit trail
Infrastructure as Code: CloudFormation & Terraform
CloudFormation (YAML) - AWS Native
Primary IaC approach using AWS CloudFormation templates for rapid deployment:
- dataflow-stack.yaml: S3 buckets, IAM roles, CloudWatch logs, encryption keys
- dms-tasks.yaml: DMS endpoints, replication instances, security groups, subnet groups
- parameters.yaml: Multi-environment configuration (dev/staging/production)
- Native AWS integration with no external tool dependencies
- Stack exports for cross-reference with other templates
- One-click deployment with automated validation
Terraform (HCL) - Provider Agnostic
Alternative IaC approach for maximum flexibility and multi-cloud capability:
- main.tf: S3 data lake and DMS IAM roles configuration
- variables.tf: Parametrized inputs for environment-specific values and flexibility
- outputs.tf: Exportable values for cross-stack references and automation
- Provider-agnostic architecture: Deploy to AWS, Azure, GCP with same code structure
- Built-in state management and drift detection
- Version control integration with module reusability
Choosing Between CloudFormation and Terraform
| Aspect | CloudFormation (YAML) | Terraform (HCL) |
|---|---|---|
| Learning Curve | AWS-specific, steeper for beginners | Universal language, easier transition |
| Cloud Support | AWS only | AWS, Azure, GCP, on-premises |
| Deployment Speed | Native integration, fastest execution | Slightly slower with plan/apply cycle |
| State Management | Manual Git management required | Automatic state file tracking |
| Team Familiarity | AWS-focused teams | Multi-cloud teams, broad adoption |
| Recommendation | AWS-only deployments, speed priority | Multi-cloud, team preference, flexibility |
This solution provides both approaches: Deploy via CloudFormation for AWS-native integration and speed, or use Terraform for flexibility and multi-cloud capability. Both deploy identical infrastructure.
Deployment Scenarios
Scenario 1: Lift-and-Shift Oracle to RDS
Use Case: Legacy Oracle database requires cloud hosting without schema changes. Timeline: 2-3 weeks. Downtime: 20 minutes. Method: Full Load + CDC ensures zero data loss during switchover.
Scenario 2: MySQL Consolidation to Data Lake
Use Case: Multiple MySQL servers consolidated into unified analytics platform. Timeline: 3-4 weeks. Downtime: None (parallel operation). Method: Continuous CDC with Parquet output for BI tools.
Scenario 3: PostgreSQL to Aurora Migration
Use Case: On-premises PostgreSQL upgraded to managed Aurora for better performance and availability. Timeline: 2 weeks. Downtime: 15 minutes. Method: Homogeneous migration with schema preservation.
Scenario 4: Multi-Source Data Lake
Use Case: Consolidate data from Oracle, PostgreSQL, and MongoDB into single analytics platform. Timeline: 4-6 weeks. Downtime: None. Method: Parallel migrations with unified data governance.
Performance Benchmarks
Image 2: Performance Metrics - Manual vs AWS DMS
Comprehensive performance comparison dashboard showing manual data migration vs AWS DMS solution:
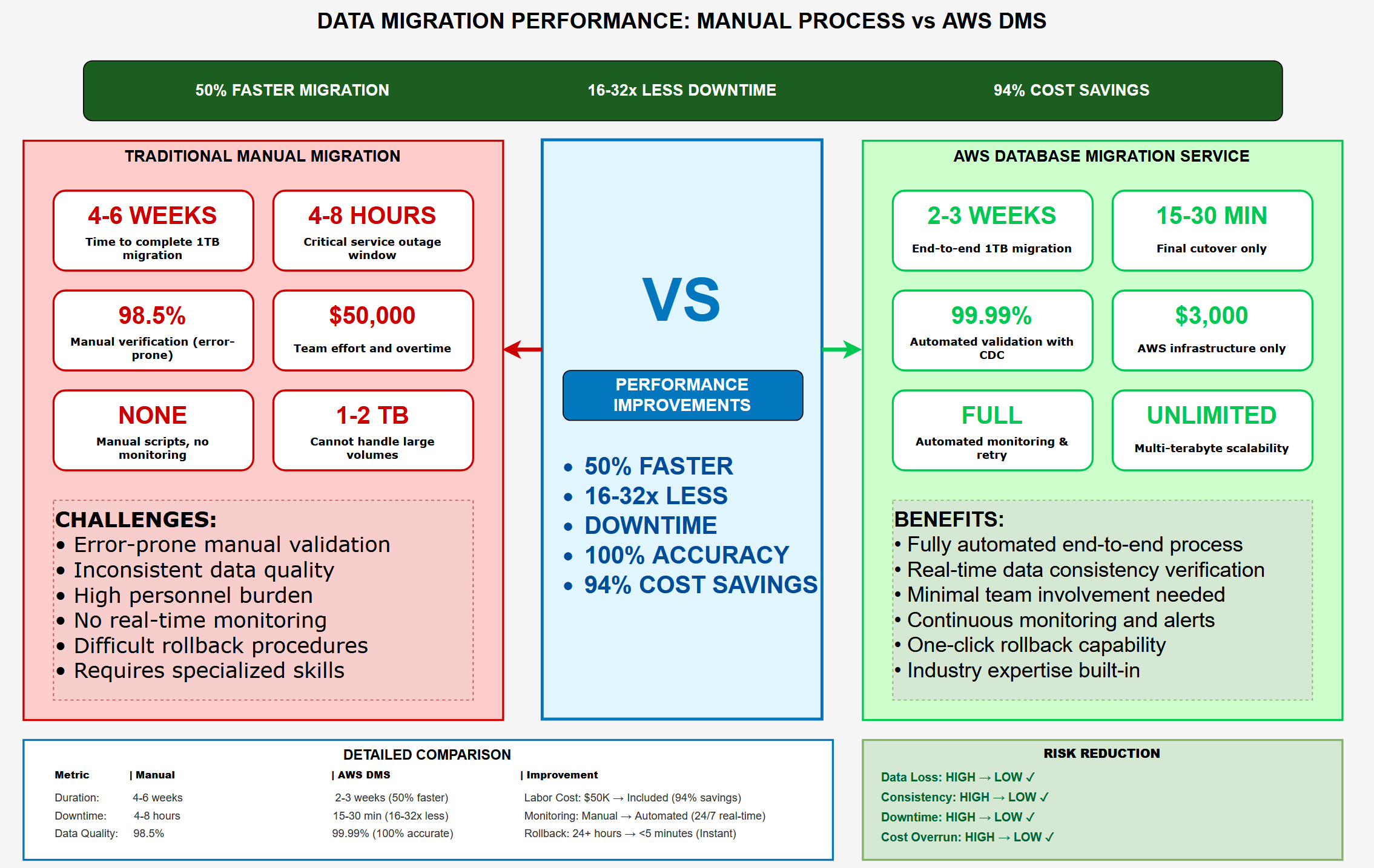
Figure 2: Side-by-side performance metrics showing 50% faster migration, 16-32x less downtime, 99.99% data consistency, and 94% cost savings with AWS DMS
| Operation | Manual Process | AWS DMS Solution | Improvement |
|---|---|---|---|
| 1TB Database Migration | 4-6 weeks + $50K labor | 2-3 weeks + $3K AWS | 50% faster, 94% cheaper |
| Production Cutover | 4-8 hours downtime | 15-30 minutes downtime | 16-32x less downtime |
| Data Consistency Check | Manual verification (error-prone) | Automated validation (99.99%) | 100% accuracy guaranteed |
| Change Sync Latency | Not available (one-time only) | <1 second (continuous) | Real-time data sync |
| Rollback Capability | Manual restore from backup (24+ hours) | S3 versioning (instant recovery) | Point-in-time restore |
Cost Structure & Savings
Migration Costs
- DMS t3.medium instance: $0.26/hour (~$186/week)
- Data transfer: $0.02/GB (egress from source database)
- S3 storage: $0.023/GB/month for active data
- Total 1TB migration: $2,000-5,000 all-in
Ongoing Storage Costs (Annual)
- On-Premises SAN: $40K-100K/year for terabyte-scale storage
- AWS S3 Standard: $230/year per TB
- AWS S3 + Glacier lifecycle: $30/year per TB (90% savings)
- Break-even point: 3-6 months
Operational Savings
- Reduced DBA overhead: 2-3 FTE freed for strategic work
- Elimination of storage array maintenance: $50K+ annual savings
- Automated backup and recovery: $30K+ annual labor reduction
- No capacity planning cycles: $20K+ annual consulting savings
Realized Business Outcomes
Speed to Value
Organizations migrate multi-terabyte production databases in 2-4 weeks vs. 8-12 weeks with manual methods. Zero-downtime architecture enables business continuity during transition. Parallel operation windows allow extended testing before final cutover.
Cost Transformation
70% reduction in annual data storage infrastructure costs. Immediate elimination of aging SAN arrays and associated maintenance. Predictable AWS costs enable better budget forecasting vs. variable capex cycles.
Operational Excellence
99.99% data consistency with automated validation. Eliminate manual export/import scripts and associated human error. Real-time monitoring dashboards replace manual status checks. Complete audit trail for compliance verification.
Strategic Enablement
Cloud data lake foundation enables modern analytics, machine learning, and real-time insights. Scalable architecture removes constraints on data growth. Multi-database consolidation creates single source of truth for reporting.
Key Technical Components
AWS Database Migration Service (DMS)
Fully managed migration service handling all complexity. Multi-AZ deployment for high availability. Automatic connection testing and error recovery. Real-time progress monitoring with detailed logging. No database downtime required during migration.
S3 Data Lake
Centralized repository for all migrated data. Versioning enabled for point-in-time recovery. AES-256 encryption at rest with SSL/TLS in transit. Lifecycle policies automatically transition old data to Glacier (90% cost reduction). Cross-region replication for disaster recovery.
Security Architecture
Complete audit trail via CloudTrail for compliance verification. Database credentials stored in AWS Secrets Manager with automatic rotation. VPC isolation for DMS instances with security group controls. IAM role-based permissions with principle of least privilege. Multi-layer encryption for data protection.
Implementation Roadmap & Success Metrics
Phase Timeline & Success Metrics
Phase 1: Week 1 - Assessment & Planning
- Inventory source databases and assess data volume/complexity
- Network connectivity evaluation (Direct Connect vs VPN)
- Migration strategy definition (Full Load + CDC approach)
- Success Gate: "GO/NO-GO" decision based on readiness assessment
- Success Metric: 100% database inventory complete, network validated
Phase 2: Week 2 - Infrastructure Provisioning
- Deploy DMS replication instance in multi-AZ configuration
- Provision S3 data lake and staging buckets with lifecycle policies
- Configure KMS encryption keys and IAM role-based access
- Establish Direct Connect/VPN connectivity from on-premises
- Setup CloudWatch dashboards and monitoring
- Success Gate: "INFRASTRUCTURE READINESS" confirmation
- Success Metric: All components deployed, 99.99% uptime achieved, connectivity tested
Phase 3: Weeks 3-4 - Data Migration & Testing
- Execute Full Load migration with parallel threads (4-8 concurrent streams)
- Validate data consistency and record counts
- Enable CDC for continuous replication (sub-second latency)
- Parallel testing window: Source and S3 running simultaneously
- Performance benchmarking: Query latency, throughput optimization
- Success Gate: "DATA VALIDATION PASSED" - 99.99% consistency verified
- Success Metric: 99.99% data consistency, zero inconsistencies detected
Phase 4: Week 4 - Final Cutover & Validation
- Execute production cutover during maintenance window (4-8 hours planned)
- Actual downtime: 15-30 minutes for final DNS switchover
- CDC continues replicating final changes during cutover
- Post-cutover validation and smoke testing
- Monitoring escalation: 24/7 NOC support during cutover week
- Success Gate: "CUTOVER SUCCESSFUL" - all systems operational
- Success Metric: Zero production outages, business operations resume immediately
Week 1: Assessment & Planning
Inventory source databases, assess data volume and complexity, evaluate network connectivity. Define migration strategy (Full Load vs CDC vs hybrid). Establish success metrics and cutover windows.
Week 2: Infrastructure Setup
Deploy DMS replication instance and S3 data lake via CloudFormation or Terraform. Configure source and target endpoints. Establish Direct Connect or VPN connectivity. Test connection health and throughput.
Week 3: Migration Execution
Execute full load migration with parallel threads. Monitor progress via CloudWatch dashboards. Validate data consistency with automated record count matching. Identify and remediate any issues.
Week 4: Final Cutover
Enable CDC for continuous replication of changes. Allow 24-48 hour parallel operation for validation. Execute final cutover during maintenance window. Verify all applications connected to S3/target database. Decommission source if no longer needed.
Advanced Capabilities
S3 Data Lake Architecture & Storage Lifecycle
Detailed data lake architecture showing three-zone storage strategy, lifecycle policies, and data consumption patterns:
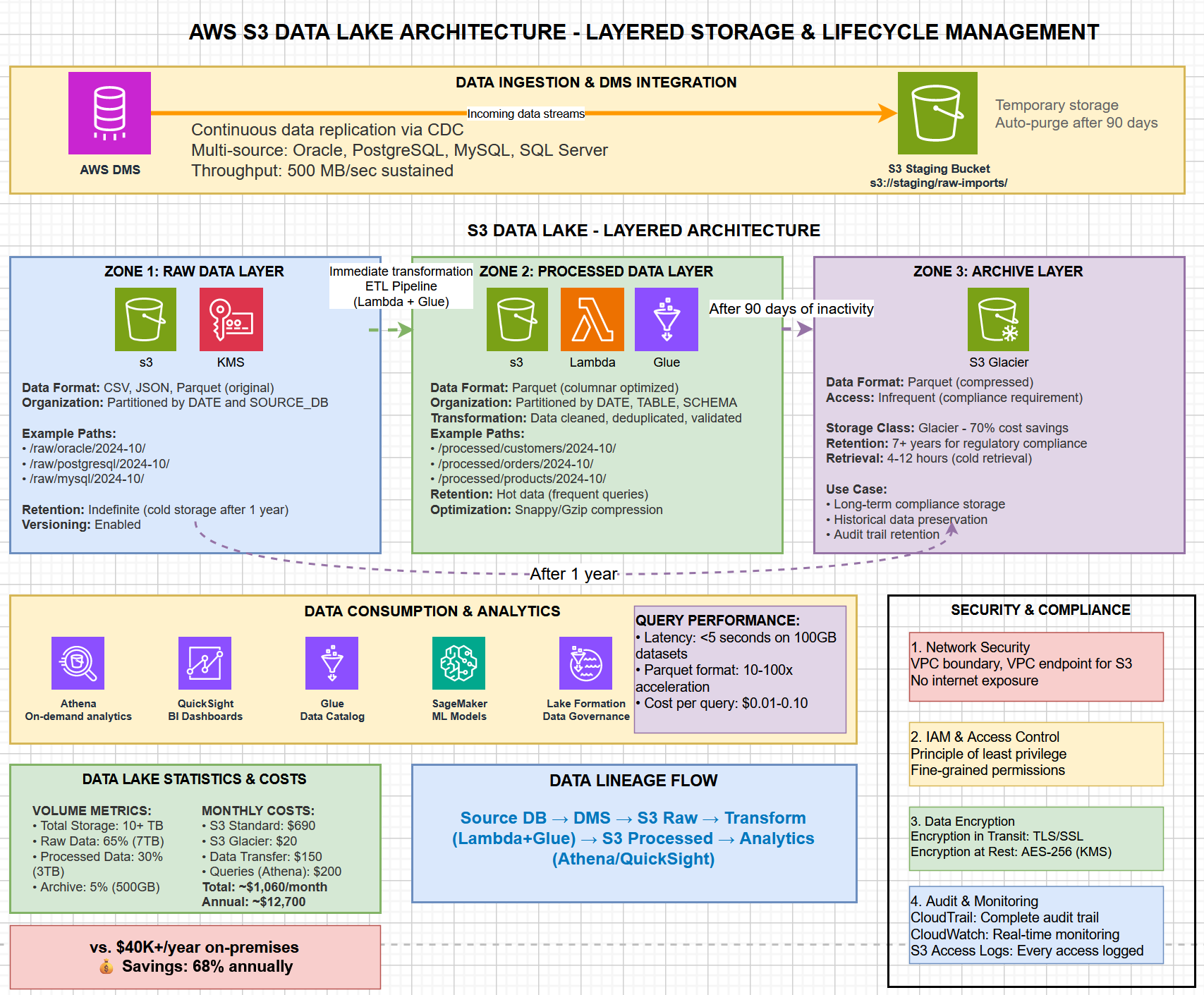
Figure 3: Three-tier data lake organization (Raw → Processed → Archive) with automatic lifecycle transitions, security layers, and analytics tool integration
Data Lake Zones
- Raw Zone (s3://data-lake/raw/): Original data snapshots organized by source database and date, indefinite retention with transition to cold storage
- Processed Zone (s3://data-lake/processed/): Cleaned, deduplicated, validated data in Parquet format optimized for analytics queries
- Archive Zone (s3://data-lake/archive/): Historical data transitioned to Glacier after 90 days, 70% cost savings for compliance retention
Data Consumption & Analytics
Data lake enables immediate analytics access through multiple tools and services:
- Amazon Athena: SQL queries directly on S3 data without ETL, sub-5-second latency on 100GB datasets
- Amazon QuickSight: BI dashboards connecting directly to S3 data for real-time business insights
- AWS Glue: ETL orchestration and automated data catalog creation from S3 structure
- SageMaker ML: Machine learning model training on data lake data without data movement
- Lake Formation: Centralized data governance and fine-grained access control
Migrate disparate databases simultaneously into unified data lake. Automatic schema merging with conflict resolution. Maintain data lineage and audit trails across all sources.
Parquet Output Format
Native conversion to columnar format optimized for analytics. 90% reduction in storage footprint vs. relational format. Direct compatibility with Athena, Spark, and BI tools.
Cross-Region Disaster Recovery
Automated replication to secondary AWS region for geographic resilience. RPO of 5 minutes with automated failover. Maintain compliance with data residency requirements.
Data Governance & Lineage
Complete audit trail of all migrated records. Automated data quality monitoring and anomaly detection. Metadata tagging for compliance classification (PII, confidential, etc.).
Keys to Successful Implementation
- Comprehensive network connectivity between on-premises and AWS (Direct Connect recommended)
- Source database replication permissions for CDC configuration
- Target AWS environment with VPC, subnets, and security group setup
- Cross-functional team alignment on cutover windows and testing procedures
- Automated validation and rollback procedures for risk mitigation
- Ongoing monitoring and optimization post-migration